0-RTT
by Rüdiger KlaehnDespite all the complexity required to enable dial by node id and direct connections, iroh has a very simple API. You create an endpoint, create connections, create streams, and then send data.
There is some complexity involved in properly closing QUIC connections, but other than that everything is pretty straightforward.
One aspect of iroh connections that is a bit more complex is 0-RTT. This blog post explains what 0-RTT is, when to use it, when not to use it, and will show a small example.
What is 0-RTT
Iroh connections are just peer to peer QUIC connections, using a fork of the quinn rust crate. QUIC is using TLS for encryption.
So to explain what 0-RTT is, it is helpful to explain how a normal TLS handshake works in detail.
We refer to logical TLS messages as just messages. Messages can be split into multiple QUIC frames, and multiple QUIC frames will be combined in QUIC packets, which will then be sent over the network. But for the purpose of explaining the handshake these details don't matter.
Normal TLS handshake
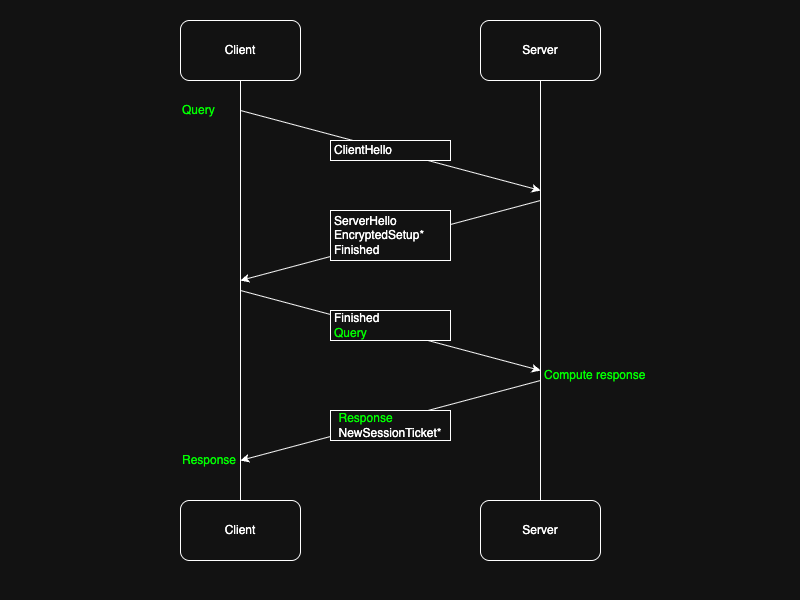
ClientHello
The connection is initiated from the client by sending a ClientHello. This message contains the TLS protocol version, random data, and the set of supported cipher suites. In addition it contains a set of ALPN strings that identify the application level protocols that the client wishes to speak.
When receiving the ClientHello, the server has information to narrow down the set of cryptographic primitives to use. The server endpoint also has a set of ALPNs it supports, so it can downselect those as well.
If the intersection of the ALPNs requested by the client and the ALPNs supported by the server is empty, the handshake will nevertheless continue.
If the intersection of cipher suites between client and server is empty however, the handshake will definitely fail. The server will not send a ServerHello, but just a TLS alert indicating a handshake failure.
ServerHello
The ServerHello message contains a random value as well as a single cipher suite that is to be used for further communication. It also contains a single ALPN selected by the server to select the application level protocol for the rest of the session - or none if there was no overlap.
So in short, the purpose of the ServerHello is to downselect the cipher suite and ALPN, and to contribute randomness for the generation of a unique session specific symmetric key.
The server will send the ServerHello, possibly additional encrypted messages for connection setup, and then a Finished message.
Session setup
Once the client has received the ServerHello, it has collected all the required information to set up the session for transporting user data. At this point the cipher suite and ALPN are fixed for the rest of the session.
In the case where there is no overlap between client and server ALPNs, in principle it is possible to fall back to a default ALPN, but this is not relevant for iroh connections.
Since the cipher suite is now fixed, the client can now use the client and server random to derive symmetric keys for additional handshake messages as well as for user data.
Every message that the client receives after the ServerHello is encrypted with the symmetric keys that are now shared knowledge on both sides.
The client processes possible additional packages from the server until it receives the Finished message. At that point it validates that it has received all setup messages form the server using a secure checksum contained in the Finished message.
User data
Now the client has ingested and validated all the messages relevant for connection setup, and has derived the keys required for user data encryption. It can finally send a Finished message itself, closing the connection setup from its side.
immediately after this, the client can send the first message of user data, encrypted with the derived application keys.
After the server receives the Finished message from the client, it can forward user data to the application space. Also at this time it will send a number of NewSessionTicket messages to the client that contains a pre-shared key for session resumption or 0-RTT in subsequent connections.
As you can see, the handshake is somewhat expensive in terms of computation, but more importantly requires a roundtrip from client to server and back before the first bit of user data can flow, even in the case where both sides have talked recently.
0-RTT handshake
In many cases, in particular for long lived connections, the overhead of the handshake is completely acceptable. But there are many protocols where there is just a very brief information exchange between a client and a server, and latency is critical. In these cases, it would be a big advantage for the client to optimistically send user data immediately after the ClientHello.
For latency critical protocols, you simply get your answer faster. But even for non latency critical protocols, the overhead is reduced because the total duration of the interaction is reduced, so there are fewer requests in flight.
0-RTT is only possible if a client has received pre shared keys from the server via NewSessionTicket messages, which is the case if they performed a full handshake in the recent past.
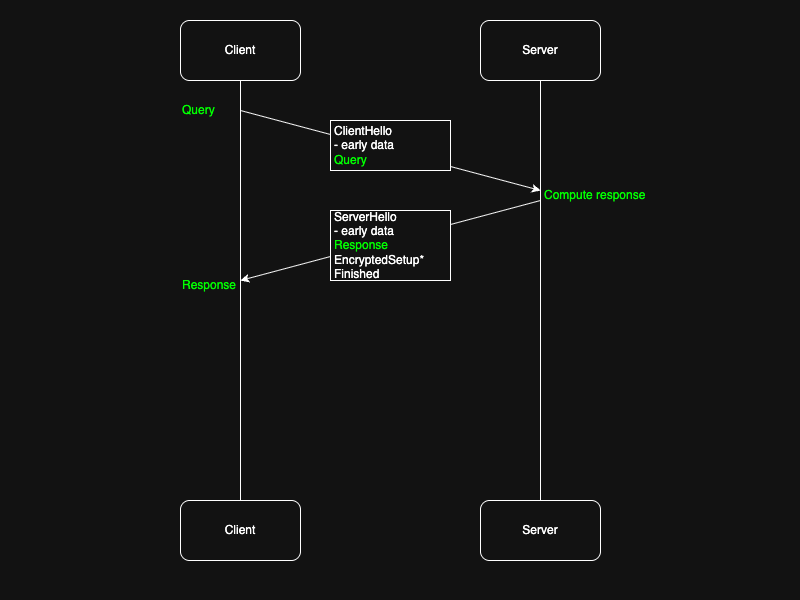
ClientHello
Like before, the client sends a ClientHello message. The ClientHello for a connection attempt using 0-RTT must contain a set of ids of pre shared keys, otherwise it is not possible for the server to decrypt subsequent user data before the full handshake is complete. In addition it has an early data flag set.
Immediately after the ClientHello, the client will send a message containing user data. Since a full exchange has not happened yet, the client has to choose one of the previously used PSKs for encryption, typically the most recent one.
Server side
On the server side, the server receives the special ClientHello. In the happy case, it still has the key for the pre shared key used by the client and will use it to decrypt subsequent messages. It will proceed with sending a ServerHello immediately, as before. This message will also have the early data flag set to indicate that the server might also send data before the handshake is complete.
Once the server receives the early user data message, if it accepts 0-rtt requests, it will attempt to decrypt the message and forward it to the application space. The application space can then answer with an early data message on its own.
Handshake completes
Regardless of early data in any direction, the normal handshake continues as before. Once the client receives a Finished message from the server, it will compute symmetric encryption keys as before and then switch to this set of keys for all subsequent messages. Likewise, once the server receives a Finished message from the client, it will compute keys and switch encryption.
Replay attacks
By now we should have a pretty good idea what 0-RTT is and why it is useful. Being able to send user data in the first UDP message seems tremendously useful. So why isn't it the default?
The client message uses a previously received pre shared key for encryption. For as long as this PSK is valid on the server, you can just re-send the exact same packet, and the user data will be sent to the application on the server side. This could be used to create unwanted changes on the server in case of a non-idempotent request, or to create a large load by sending the same request millions of times.
In addition, due to the fact that the process of computing the session keys from the PSK is - and has to be - fully deterministic, once an attacker has access to the key, they can decrypt all past or future 0-RTT data encrypted using that key. Since the session switches encryption after the handshake completes, data after handshake completion is not affected by this.
So in general you should only use 0-RTT for protocols where all requests are idempotent (so receiving the same message multiple times does not change the outcome) and where receiving and answering the message is not a lot of effort, so processing a message several times does not create a problem.
You should also not use 0-RTT for extremely security critical use cases.
You can make protocols idempotent by adding sequence numbers or random unique message ids in your application level protocol, at the expense of some server side state. The same approach can also be used to reduce the impact of receiving the same message multiple times.
Usage in iroh
Now let's implement a simple 0rtt service in iroh. It is going ot be a simple echo service, where we just read a tiny request and echo it back byte for byte.
Accept side
On the accept side, this is relatively easy. We do have to opt in to allowing 0rtt requests, since as we have seen 0rtt has reduced security guarantees compared to normal requests with a full handshake before the data starts to flow.
When we get a Connecting by calling incoming.accept()?, we try to convert it into a 0rtt connection using .into_0rtt(). If this succeeds, we return the connection. If not, we get back the Connecting and await it to get a Connection like normal. Once that is done, the code is identical to a non 0rtt echo service.
let connecting = incoming.accept()?;
let connection = match connecting.into_0rtt() {
Ok((connection, _)) => connection,
Err(connecting) => connecting.await?,
};
let (mut send, mut recv) = connection.accept_bi().await?;
let data = recv.read_to_end(8).await?;
send.write_all(&data).await?;
send.finish()?;
connection.closed().await;
Connect side
The connect side is more tricky, because we need to deal with the case where we can't initiate a 0rtt connection because we don't have tickets from a previous connection, as well as the case where the remote side does not accept a 0rtt connection, e.g. because it no longer has the corresponding secret.
We first define a helper fn for the entire ping protocol:
async fn pingpong(
connection: &Connection,
proceed: impl Future<Output = bool>,
x: u64,
) -> anyhow::Result<()> {
let (mut send, mut recv) = connection.open_bi().await?;
let data = x.to_be_bytes();
send.write_all(&data).await?;
send.finish()?;
let recv = if proceed.await {
recv
} else {
let (mut send, mut recv) = connection.open_bi().await?;
send.write_all(&data).await?;
send.finish()?;
recv
};
let echo = recv.read_to_end(8).await?;
anyhow::ensure!(echo == data);
Ok(())
}
It creates a bidi stream, and immediately sends the payload to the other side. If the proceed future returns true, it tries to read the result from the initial recv stream, otherwise it starts with a new bidi stream. Once it has read the echo result, it ensures that it is identical to what was sent.
Other than the proceed future, this is exactly as you would write this without 0rtt.
Now the function that actually tries to send a 0rtt request:
async fn pingpong_0rtt(connecting: Connecting, i: u64) -> anyhow::Result<Connection> {
let connection = match connecting.into_0rtt() {
Ok((connection, accepted)) => {
trace!("0-RTT possible from our side");
pingpong(&connection, accepted, i).await?;
connection
}
Err(connecting) => {
trace!("0-RTT not possible from our side");
let connection = connecting.await?;
pingpong(&connection, future::ready(true), i).await?;
connection
}
};
Ok(connection)
}
As on the accept side, we try to convert the Connecting into a 0rtt connection using .into_0rtt().
If this succeeds, we get back a preliminary connection and a future that resolves once the full handshake is complete. We pass that future into the fn defined above.
If it fails, we just call the above fn with a dummy future that immediately succeeds, since in this case we only get the connection after a full handshake.
Trying it out
We can of course try this out locally, but that won't show a big difference between both versions, since the latency on localhost is extremely low.
So we run the accept part on a machine that is far away. In this case I am running the accept part on a machine in us-east-1, and the connect part on my local machine in europe.
Just for reference, here is the current ping to this machine:
❯ ping xx.xx.xx.xx
PING xx.xx.xx.xx (xx.xx.xx.xx): 56 data bytes
64 bytes from xx.xx.xx.xx: icmp_seq=0 ttl=47 time=114.940 ms
64 bytes from xx.xx.xx.xx: icmp_seq=1 ttl=47 time=113.786 ms
64 bytes from xx.xx.xx.xx: icmp_seq=2 ttl=47 time=110.527 ms
64 bytes from xx.xx.xx.xx: icmp_seq=3 ttl=47 time=110.960 ms
So, on the order of 120 ms. The whole point of a 0-RTT request is to get data back in the first roundtrip, so we expect a similar value for the send to receive delay.
Accept side
Running the accept side prints a ticket that we need to connect. We want this to be a pure test of 0rtt latency, not node discovery latency. So in the code we have disabled node resolution and made sure that the ticket contains the direct address of the node. This also means that the accept side must be running on machine with a public IP address.
Listening on: NodeAddr { node_id: PublicKey(1c64a26558be5f114375977a32d411ba5610577d4935ecb3f00b015320c32e78), relay_url: None, direct_addresses: { ... } }
Node ID: PublicKey(1c64a26558be5f114375977a32d411ba5610577d4935ecb3f00b015320c32e78)
Ticket: nodeaa...
Connect side
On the connect side, we just need to specify the node ticket to connect to and optionally the number of rounds.
We set a debug level to see what's going on:
RUST_LOG=0rtt=trace cargo run --release --example 0rtt nodeaa...
2025-05-22T15:10:02.005378Z TRACE 0rtt: 0-RTT not possible from our side
2025-05-22T15:10:02.270286Z DEBUG 0rtt: round 0: 266358 us
2025-05-22T15:10:02.272468Z TRACE 0rtt: 0-RTT possible from our side
2025-05-22T15:10:02.402081Z DEBUG 0rtt: round 1: 131681 us
2025-05-22T15:10:02.404558Z TRACE 0rtt: 0-RTT possible from our side
2025-05-22T15:10:02.533311Z DEBUG 0rtt: round 2: 130064 us
2025-05-22T15:10:02.534596Z TRACE 0rtt: 0-RTT not possible from our side
2025-05-22T15:10:02.792593Z DEBUG 0rtt: round 3: 259101 us
2025-05-22T15:10:02.793975Z TRACE 0rtt: 0-RTT possible from our side
2025-05-22T15:10:02.924554Z DEBUG 0rtt: round 4: 131883 us
2025-05-22T15:10:02.926120Z TRACE 0rtt: 0-RTT possible from our side
2025-05-22T15:10:03.055240Z DEBUG 0rtt: round 5: 130586 us
2025-05-22T15:10:03.056524Z TRACE 0rtt: 0-RTT not possible from our side
2025-05-22T15:10:03.316197Z DEBUG 0rtt: round 6: 260394 us
2025-05-22T15:10:03.317830Z TRACE 0rtt: 0-RTT possible from our side
Now this is weird.
The initial connection is not 0-RTT, which is expected. The two nodes haven't ever talked, so there is no pre shared secret they can use to communicate.
The next two rounds are 0-RTT, as expected, and have roughly the expected roundtrip times.
But then we get a non 0-RTT connection on the 4th round. What's going on?
The issue is that 0-RTT is done using single-use tickets. After each completed handshake, you get a number of these tickets, by default 2. And as soon as the tickets are used up, the client can not even attempt to do a 0-rtt request because it has run out of tickets to use.
In the code so far we close the connection immediately after receiving the user data response. So we don't wait for the full handshake to complete, and also don't get any additional tickets.
pingpong_0rtt(connecting, i).await?
connection.close(0u8.into(), b"");
Waiting for new tickets
There are two ways to solve this. The tickets for 0-RTT connections are single use in quinn, as recommended in the TLS spec: https://datatracker.ietf.org/doc/html/rfc8446#appendix-C.4 . We can get new tickets via a connection that was initiated with 0-RTT, but only if we allow time for the handshake to complete.
There is currently no quinn API to wait for the handshake to complete or to wait for session tickets. But we can just sleep for two times the current round trip time before closing the connection. This is a crude way to allow for enough time for the two NewSessionTickets to be received.
Since we don't want to hold up the user space just because we are waiting for an additional message, we do this in a tokio task.
tokio::spawn(async move {
tokio::time::sleep(connection.rtt() * 2).await;
connection.close(0u8.into(), b"");
})
In the future we would want to replace the crude sleep with a more precise API that waits exactly until at least one NewSessionTicket message has been received.
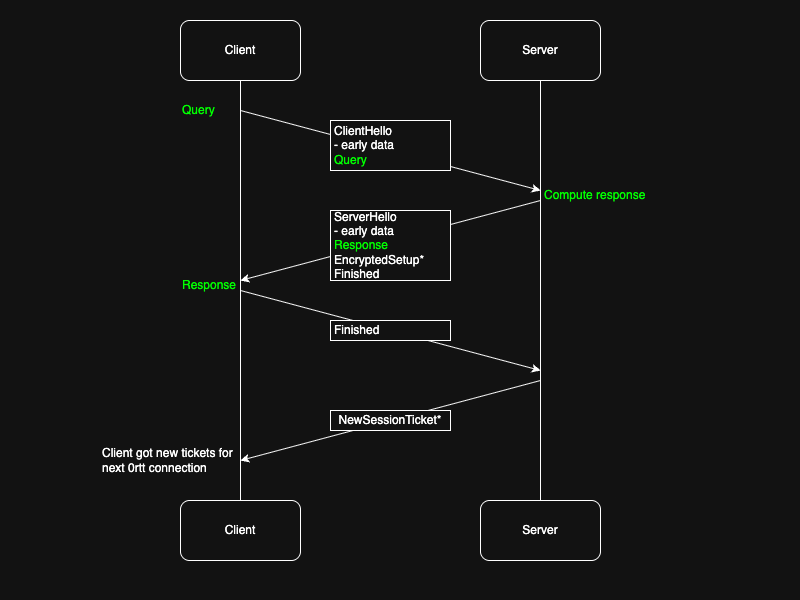
Sending more tickets
Another possible solution would be to just reconfigure the server to send more session tickets. E.g. you could send 8 instead of 2. The downside of this is that you send additional data, but the upside is that you get more 0-RTT connections per full handshake. Alas, this is currently not configurable without having to modify iroh.
Reusing tickets
The TLS spec says that you SHOULD NOT reuse tickets - you should treat them as single use on the client side. But SHOULD NOT just discourages this, but does not outright forbid it. And due to its stateless nature the server side will not reject multiple 0-RTT connection attempts using the same ticket.
So in theory you could modify the client to just reuse the ticket.
So what to do?
Let's take a step back and think about when you would use 0-RTT. If you have two nodes that communicate frequently every few seconds or even minutes, it is probably best to just leave the connection open. A normal QUIC connection has very low overhead, and even for a hole-punched iroh QUIC connection the overhead of occasional messages to keep the connection open is very acceptable.
So you would use 0-RTT if communication is in small bursts spaced many minutes to hours apart, but nevertheless latency is important. In this case the most important property of 0-RTT is that the application gets a response after the minimal physically possible delay. Keeping the connection open for another small time period to refresh the pre shared keys is not a big deal.
Wireshark
You can of course just take the content of this blog post and use it. But if you want to know exactly what is going on on the wire, here is how you would do it (I write this partly as future reference for myself).
To see the handshake packets in all detail, you need a package capture tool like wireshark. If you run this example with a remote node, it is pretty easy to configure a filter that captures just the traffic of the example.
When wireshark starts up you choose the network interface that will be used for communication, e.g. WiFi: en0 for the wireless connection on a mac. This is the network interface used to communicate with the outside world.
Next you want to select only UDP traffic to the destination IP address where the accept side runs. So you end up with a filter rule like this:
udp and host xx.xx.xx.xx
This is sufficient, since there is no other traffic going to that host.
Now run the program with a small number of rounds and see what is being captured.
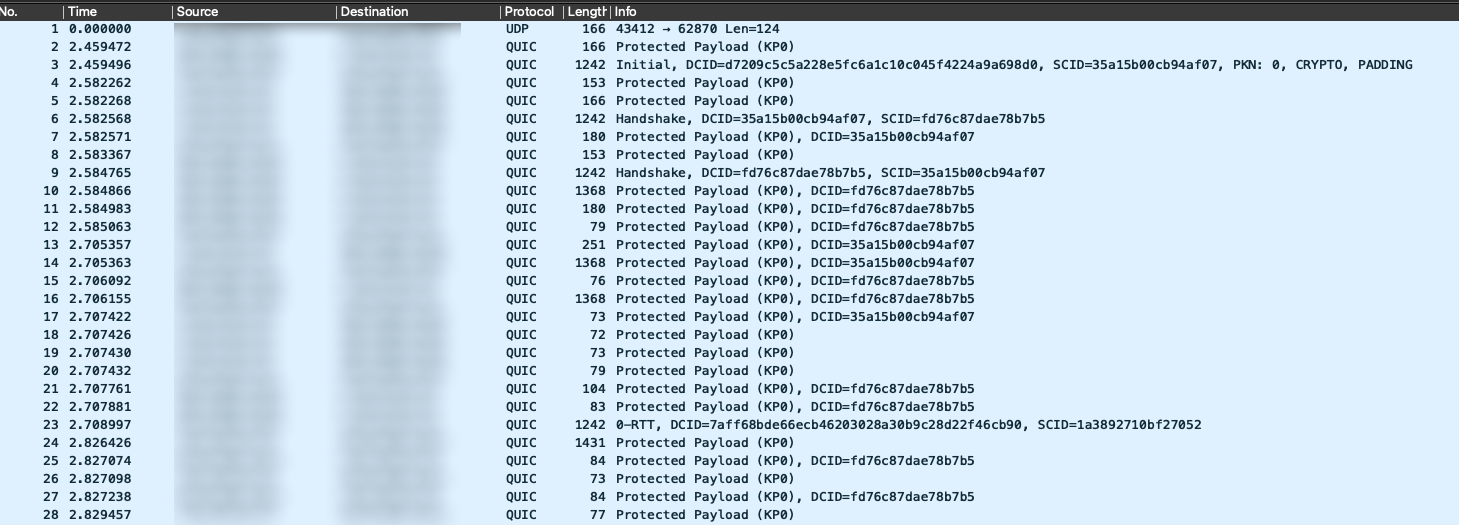
This is already quite interesting. Unfortunately there is a lot you can learn about traffic content by just looking at packet size and timing. But to really understand what is going on we would of course have to look into the packets, and this is not possible for all but the initial packets due to encryption.
Fortunately iroh has a feature to persist the required information for decrypting the packet content. In the endpoint builder you can specify .keylog(true). This will check for an environment variable SSLKEYLOGFILE, and if it exists, write all information required for decryption into that file.
let endpoint = iroh::Endpoint::builder()
.relay_mode(iroh::RelayMode::Disabled)
.bind()
.await?;
Now we just need to run the connect side again with SSLKEYLOGFILE set, e.g.
SSLKEYLOGFILE=keylog.txt RUST_LOG=0rtt=debug cargo run --release --example 0rtt --rounds 10 nodeab...
After running this, keylog.txt will contain all the secrets required to decode the captured packages. You don't have to fully understand what is in there, the main thing is that wireshark does understand it.
CLIENT_HANDSHAKE_TRAFFIC_SECRET 044a5d42b163208ff7a45ba0e0a9f6f6cd1eb0f49de32c9c4c09d302f0c7738c dd18f63d3f386e82ef91677f3780ced83f70f0b51641cb5952e684602bc75cb877d42f81bdfd81b799e85deebcb4f798
SERVER_HANDSHAKE_TRAFFIC_SECRET 044a5d42b163208ff7a45ba0e0a9f6f6cd1eb0f49de32c9c4c09d302f0c7738c 4ee28dfd71554bf7ddf3e766a0ac8abcfb08431734d75d366b6efeb21efc903d577ebf2e1c670262f936a46ea7d68b20
CLIENT_TRAFFIC_SECRET_0 044a5d42b163208ff7a45ba0e0a9f6f6cd1eb0f49de32c9c4c09d302f0c7738c 1df6da6b422417e95274a53cddfc96e94e2697be54aa977d2f53f4b838528d8c72df618f5f78369b4b925ad3395e736e
SERVER_TRAFFIC_SECRET_0 044a5d42b163208ff7a45ba0e0a9f6f6cd1eb0f49de32c9c4c09d302f0c7738c c82902a43c797c5687ce590d9cc2660416f018a854990ad801913b725cd0f921bf7b8e0a74a248d20c5742c0759e0b41
EXPORTER_SECRET 044a5d42b163208ff7a45ba0e0a9f6f6cd1eb0f49de32c9c4c09d302f0c7738c 0a8e42dea70dca44370072fd93295305e0672e2a0e681e1d1041ac5022d5f2151bdb48e8b7c1935f65bf03882c1c4a2a
...
But really, there is no deep magic going on here. These are just the secrets that are being exchanged in ClientHello and ServerHello during the handshake.
Once we tell wireshark to use the keylog file, we can inspect the decrypted packet content and can also see a bit more information in the text view:
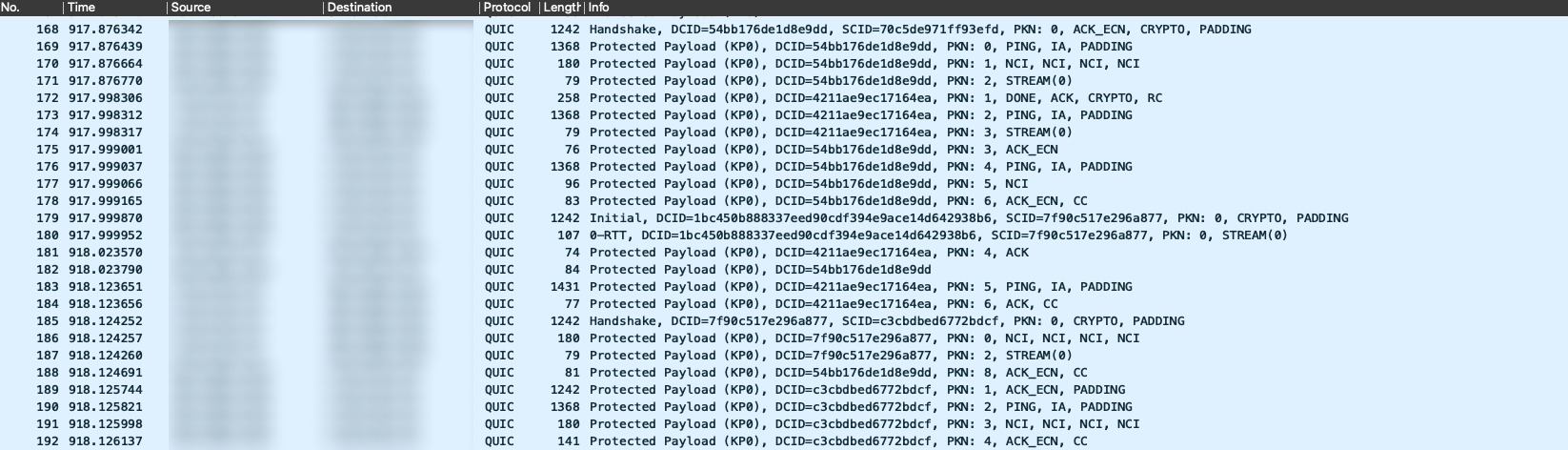
Explaining the packet content would be a blog post of its own. But we can now drill down to an individual packet, look at the decrypted content, and find our big endian encoded ping sequence number.

To get started, take a look at our docs, dive directly into the code, or chat with us in our discord channel.